
Dies ist der erste Artikel in der Reihe „Entwicklung einer eigenen Programmiersprache in Java“, in dem der gesamte Weg der Erstellung einer Programmiersprache sowie der Erstellung und Pflege von Werkzeugen für diese Sprache am Beispiel der Entwicklung einer einfachen Sprache aufgezeigt wird. Am Ende dieses Artikels werden wir einen Interpreter implementieren, der zur Ausführung von Programmen in unserer Sprache verwendet werden kann.
Jede Programmiersprache hat eine Syntax, die in eine Datenstruktur umgewandelt werden muss, die für die Validierung, Transformation und Ausführung geeignet ist. In der Regel handelt es sich bei einer solchen Datenstruktur um einen abstrakten Syntaxbaum (AST). Jeder Knoten des Baums steht für ein Konstrukt, das im Quellcode vorkommt. Der Quellcode wird von einem Parser geparst und die Ausgabe ist ein AST.
Sprachen werden schon seit langem entwickelt, so dass wir heute über eine Reihe ausgereifter Werkzeuge verfügen, darunter auch Parsergeneratoren. Parsergeneratoren nehmen als Eingabe eine Beschreibung der Grammatik einer bestimmten Sprache, und die Ausgabe besteht aus Parsern, Interpretern und Compilern.
In diesem Artikel wird das Werkzeug ANTLR betrachtet. ANTLR ist ein Dienstprogramm, das als Eingabe eine Grammatik in Form von RBNFs erhält und Schnittstellen/Klassen (in unserem Fall ist es Java-Code) für das Parsen von Programmen ausgibt. Die Liste der Sprachen, für die Parser generiert werden, finden Sie hier.
Beispielgrammatik
Bevor wir uns der eigentlichen Grammatik zuwenden, wollen wir versuchen, einige der Regeln einer typischen Programmiersprache in Worte zu fassen:
- VARIABLE – ist ein IDENTIFIER
- DIGITAL – ist eines der Zeichen 0 1 1 2 3 4 5 6 7 8 9
- NUMBER – ist ein oder mehrere Elemente vom Typ DIGITAL.
- EXPRESSION – ist eine NUMBER
- EXPRESSION – ist eine VARIABLE
- EXPRESSION – ist ein EXPRESSION ‚+‘ EXPRESSION
- EXPRESSION – ist ‚(‚EXPRESSION‘)‘)
Wie Sie aus dieser Liste ersehen können, ist eine Sprachgrammatik eine Menge von Regeln, die rekursive Verknüpfungen haben können. Jede Regel kann sich auf sich selbst oder auf eine andere Regel beziehen. ANTLR hat in seinem Arsenal viele Operatoren, um solche Regeln zu beschreiben.
; Ende der Regelmarke
| Alternativer Betreiber
.. Bereichsoperator
~ Verleugnung
. Irgendein Charakter
= Aufgabe
(…) Unterregel
(…)* Unterregel 0 Mal oder öfter wiederholen
(…)+ Unterregel mindestens einmal wiederholen
(…)? Unterregel fehlt möglicherweise
{…} Ssemantische Aktionen (in der Sprache, die als Ausgabe verwendet wird – zum Beispiel Java)
[…] Regelparameter
Beispiele für Regeln in ANTLR
Das folgende Beispiel beschreibt die Regeln für ganze Zahlen und Fließkommazahlen:
FLOAT : NUMBER ‚.‚ NUMBER ;
Es ist sehr wichtig zu wissen, dass die Grammatik nur die Syntax der Sprache beschreibt, aus der der Parser generiert wird. Der Parser wird einen AST erzeugen, der zur Implementierung der Semantik der Sprache verwendet werden kann. Im vorigen Beispiel haben wir eine Regel zum Parsen einer ganzen Zahl definiert, aber wir haben nicht beschrieben, wie viel Speicherplatz die Zahl belegt (8 Bit, 16, …), ob die Zahl vorzeichenbehaftet oder vorzeichenlos ist. In einigen Programmiersprachen kann man zum Beispiel eine Variable verwenden, ohne sie zu deklarieren. Es ist auch möglich, den Typ einer Variablen nicht zu deklarieren; in diesem Fall wird der Typ zur Laufzeit automatisch bestimmt. Alle diese Regeln der Sprachsemantik werden nicht in der Grammatik beschrieben, sondern sind in einem anderen Teil der Sprache implementiert.
ANTLR-Lexeme und -Ausdrücke
Die ANTLR-Grammatik besteht aus zwei Arten von Regeln: Lexeme und Ausdrücke, die dazu dienen, die Struktur der Grammatik zu definieren und die Eingabedaten zu parsen.
Lexeme (oder Token) sind Regeln, die einzelne lexikalische Elemente der Eingabesprache definieren, wie z. B. Zahlen, Bezeichner, Operationszeichen usw. Jedes Lexem entspricht einem bestimmten Typ von Token, der vom Parser für die weitere Verarbeitung verwendet wird. Der lexikalische Analysator scannt den Eingabetext, zerlegt ihn in Token und erstellt eine Folge von Token, die dann an den Parser weitergegeben werden. Token werden in Großbuchstaben geschrieben (z. B. NUMBER, IDENTIFIER).
Ausdrücke sind Regeln, die die Struktur der Grammatik der Eingabesprache definieren. Sie beschreiben, wie Token zueinander in Beziehung stehen und wie sie zu komplexeren Konstrukten kombiniert werden können. Ausdrücke können sowohl Verweise auf Token als auch auf andere Ausdrücke enthalten. Sie werden in camelCase-Schreibweise geschrieben (zum Beispiel: expression, functionDefinition).
Der Unterschied zwischen Token und Ausdrücken in ANTLR besteht also darin, dass Token die einzelnen lexikalischen Elemente der Eingabesprache definieren und sie in Token umwandeln, während Ausdrücke die Struktur der Grammatik definieren und beschreiben, wie Token zu komplexeren Konstrukten verknüpft werden.
Sprachliche Anforderungen
Bevor wir mit der Implementierung einer Sprache beginnen, müssen wir entscheiden, welche Funktionen sie unterstützen soll. Für unsere Aufgabe, die wir zu Ausbildungszwecken durchführen, werden wir eine einfache Grammatik verwenden. Die Sprache wird die folgenden Konstrukte unterstützen:
- Variablen (Typen String, Long, Double);
- Zuweisungsoperator (=);
- Arithmetische Operationen (+, -, *, /);
- Vergleichsoperatoren (>, <, >=, <=, ==, !=);
- Bedingungsoperatoren (if, else);
- Funktionen;
- Auf der Konsole drucken (integrierte println-Anweisung).
Grammatik
Schließlich eine vollständige Beschreibung der Grammatik der Sprache:
// Grundregel der Grammatik
program: (statement)* EOF;
// Liste möglicher Aussagen
statement: variableDeclaration
| assignment
| functionDefinition
| functionCall
| println
| return
| ifStatement
| blockStatement
;
// Liste möglicher Ausdrücke
expression: ‚(‚ expression ‚)‚ #parenthesisExpr
| left=expression op=(ASTERISK | SLASH) right=expression #mulDivExpr
| left=expression op=(PLUS | MINUS) right=expression #plusMinusExpr
| left=expression compOperator right=expression #compExpr
| IDENTIFIER #idExp
| NUMBER #numExpr
| DOUBLE_NUMBER #doubleExpr
| STRING_LITERAL #stringExpr
| functionCall #funcCallExpr
;
// Beschreibungen einzelner Ausdrücke und Aussagen
variableDeclaration: ‚var‚ IDENTIFIER ‚=‚ expression ;
assignment: IDENTIFIER ‚=‚ expression ;
compOperator: op=(LESS | LESS_OR_EQUAL | EQUAL | NOT_EQUAL | GREATER | GREATER_OR_EQUAL) ;
println: ‚println‚ expression ;
return: ‚return‚ expression ;
blockStatement: ‚{‚ (statement)* ‚}‚ ;
functionCall: IDENTIFIER ‚(‚ (expression (‚,‚ expression)*)? ‚)‚ ;
functionDefinition: ‚fun‚ name=IDENTIFIER ‚(‚ (IDENTIFIER (‚,‚ IDENTIFIER)*)? ‚)‚ ‚{‚ (statement)* ‚}‚ ;
ifStatement: ‚if‚ ‚(‚ expression ‚)‚ statement elseStatement? ;
elseStatement: ‚else‚ statement ;
// Liste der Token
IDENTIFIER : [a-zA-Z_] [a-zA-Z_0-9]* ;
NUMBER : [0-9]+ ;
DOUBLE_NUMBER : NUMBER ‚.‚ NUMBER ;
STRING_LITERAL : ‚„‚ (~[„])* ‚„‚ ;
ASTERISK : ‚*‚ ;
SLASH : ‚/‚ ;
PLUS : ‚+‚ ;
MINUS : ‚–‚ ;
ASSIGN : ‚=‚ ;
EQUAL : ‚==‚ ;
NOT_EQUAL : ‚!=‚ ;
LESS : ‚<‚ ;
LESS_OR_EQUAL : ‚<=‚ ;
GREATER : ‚>‚ ;
GREATER_OR_EQUAL : ‚>=‚ ;
SPACE : [ \r\n\t]+ -> skip;
LINE_COMMENT : ‚//‚ ~[\n\r]* -> skip;
Wie Sie vielleicht schon erraten haben, heißt unsere Sprache Jimple (abgeleitet von Jvm Simple). Vielleicht lohnt es sich, einige Punkte zu erläutern, die beim ersten Kennenlernen von ANTLR vielleicht nicht offensichtlich sind.
Labels
Bei der Beschreibung der Regeln einiger Operationen wurde das Label op verwendet, so dass wir dieses Label als Namen der Variablen verwenden können, die den Wert des Operators enthält. Im Prinzip könnten wir auf die Angabe von Labels verzichten, aber in diesem Fall müssen wir zusätzlichen Code schreiben, um den Wert des Operators aus dem Parse-Baum zu erhalten.
Benannte Regelalternativen
Wenn in ANTLR eine Regel mit mehreren Alternativen definiert wird, kann jeder von ihnen ein Name gegeben werden und wird dann ein separater Verarbeitungsknoten im Baum sein. Dies ist sehr praktisch, wenn es notwendig ist, die Verarbeitung jeder Regelalternative in eine separate Methode zu legen. Es ist wichtig, dass entweder alle Alternativen oder keine von ihnen einen Namen erhalten. Das folgende Beispiel zeigt, wie das aussehen kann:
| IDENTIFIER #idExp
| NUMBER #numExpr
ANTLR erzeugt den folgenden Code:
T visitParenthesisExpr(ParenthesisExprContext ctx);
T visitIdExp(IdExpContext ctx);
T visitNumExpr(NumExprContext ctx);
}
Kanäle
In ANTLR gibt es ein solches Konstrukt als Kanal (channel). Normalerweise werden Kanäle verwendet, um mit Kommentaren zu arbeiten, aber da wir in den meisten Fällen nicht prüfen müssen, ob es Kommentare gibt, sollten sie mit -> skip verworfen werden, was wir auch verwendet haben. Es gibt jedoch Fälle, in denen wir die Bedeutung von Kommentaren oder anderen Konstrukten interpretieren müssen, dann verwenden Sie Kanäle. ANTLR hat bereits einen eingebauten Kanal namens HIDDEN, den Sie verwenden können, oder Sie deklarieren Ihre eigenen Kanäle für bestimmte Zwecke. Auf diese Kanäle können Sie beim Parsen des Codes weiter zugreifen.
Beispiel für die Ankündigung und Nutzung eines Kanals
LINE_COMMENT : ‚//‚ ~[rn]+ -> channel(MYLINECOMMENT) ;
Fragmente
Zusätzlich zu den Token gibt es in ANTLR ein Konzept, das als Fragment (fragment) bezeichnet wird. Regeln mit dem Präfix fragment können nur von anderen Regeln im Lexer aufgerufen werden. Sie sind selbst keine Token. Im folgenden Beispiel haben wir die Definitionen von Zahlen für verschiedene Zahlensysteme in Fragmenten zusammengefasst.
fragment DIGITS: ‚1‚..‚9‚ ‚0‚..‚9‚*;
fragment OCTAL_DIGITS: ‚0‚ ‚0‚..‚7‚+;
fragment HEX_DIGITS: ‚0x‚ (‚0‚..‚9‚ | ‚a‚..‚f‚ | ‚A‚..‚F‚)+;
So wird eine Zahl in einem beliebigen Zahlensystem (zum Beispiel «123», «0762» oder «0xac1») als NUMBER-Token und nicht als DIGITS, OCTAL_DIGITS oder HEX_DIGITS behandelt. Fragmente werden in Jimple nicht verwendet.
Instrumente
Bevor wir mit der Generierung des Parsers beginnen, müssen wir Werkzeuge für die Arbeit mit ANTLR einrichten. Wie wir wissen, ist ein gutes und bequemes Werkzeug die Hälfte des Erfolgs. Zu diesem Zweck müssen wir die ANTLR-Bibliothek herunterladen und Skripte schreiben, um sie auszuführen. Es gibt auch Maven/Gradle/IntelliJ IDEA Plugins, die wir in diesem Artikel nicht verwenden werden, die aber für eine produktive Entwicklung nützlich sein können.
Wir benötigen die folgenden Skripte:
Skript antlr4.sh
Skript grun.sh
Parser-Generierung
Speichern Sie die Grammatik in der Datei Jimple.g4. Führen Sie dann das Skript wie folgt aus:
Mit dem Parameter -package können Sie das Java-package angeben, in dem der Code generiert werden soll. Mit dem Parameter -visitor können Sie die Schnittstelle JimpleVisitor generieren, die das Visitor-Muster implementiert.
Nach erfolgreicher Ausführung des Skripts erscheinen mehrere Dateien im aktuellen Verzeichnis: JimpleParser.java, JimpleLexer.java, JimpleListener.java, JimpleVisitor.java.
Die ersten beiden Dateien enthalten den generierten Parser- bzw. Lexer-Code. Die beiden anderen Dateien enthalten die Schnittstellen für die Arbeit mit dem Parse-Baum. In diesem Artikel werden wir die JimpleVisitor-Schnittstelle verwenden, genauer gesagt ist JimpleBaseVisitor— ebenfalls eine generierte Klasse, die die JimpleVisitor-Schnittstelle implementiert und Implementierungen aller Methoden enthält. So können wir nur die Methoden überschreiben, die wir benötigen.
Implementierung des Interpreters
Schließlich kommen wir zum interessantesten Teil — der Implementierung des Interpreters. Obwohl wir uns in diesem Artikel nicht mit der Überprüfung des Codes auf Fehler befassen werden, werden wir dennoch Interpretationsfehler implementieren. Als erstes erstellen wir eine Klasse JimpleInterpreter mit der eval-Methode, deren Input ein String mit Jimple-Code sein wird. Als nächstes müssen wir den Quellcode mit JimpleLexer in Token zerlegen und dann mit JimpleParser einen AST-Baum erstellen.
public Object eval(final String input) {
// Parsen des Quellcodes in Token
final JimpleLexer lexer = new JimpleLexer(CharStreams.fromString(input));
// Erstellen Sie einen AST-Baum
final JimpleParser parser = new JimpleParser(new CommonTokenStream(lexer));
// Erstellen Sie ein Objekt der Klasse JimpleInterpreterVisitor
final JimpleInterpreterVisitor interpreterVisitor = new JimpleInterpreterVisitor(new JimpleContextImpl(stdout));
// Starten Sie den Interpreter
return interpreterVisitor.visitProgram(parser.program());
}
}
Wir haben einen Syntaxbaum. Fügen wir nun mit Hilfe der von uns geschriebenen Klasse JimpleInterpreterVisitor, die den AST durch Aufruf der entsprechenden Methoden durchläuft, einige Semantiken hinzu. Da die Wurzelregel unserer Grammatik die program Regel ist (siehe oben program: (statement)* EOF), beginnt die Baumdurchquerung dort. Dazu rufen wir die Standardmethode visitProgram des JimpleInterpreterVisitor-Objekts auf, mit einem Objekt der Klasse ProgramContext als Eingabe. Die ANTLR-Implementierung besteht aus dem Aufruf der visitChildren(RuleNode node-Methode, die alle Kinder eines bestimmten Baumknotens durchläuft und für jedes von ihnen die visit-Methode aufruft.
public class JimpleBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements JimpleVisitor<T> {
@Override
public T visitProgram(JimpleParser.ProgramContext ctx) {
return visitChildren(ctx);
}
// Andere Methoden werden der Kürze halber weggelassen
}
Wie Sie sehen, ist JimpleBaseVisitor eine generische Klasse, für die Sie den Verarbeitungstyp für jeden Knoten definieren müssen. In unserem Fall ist dies die Object-Klasse, da Ausdrücke Werte unterschiedlichen Typs zurückgeben können. Normalerweise muss ein Ausdruck einen Wert zurückgeben, eine Anweisung gibt jedoch nichts zurück. Das ist ihr Unterschied. Bei Genehmigung können wir null zurückgeben. Um jedoch nicht versehentlich auf eine NullPointerException zu stoßen, geben wir anstelle von null ein Objekt vom Typ Object zurück, das global in der JimpleInterpreter-Klasse definiert ist:
Wie Sie sehen können, JimpleBaseVisitor — ist eine generische Klasse, für die wir die Art der Verarbeitung für jeden Knoten definieren müssen. In unserem Fall ist dies die Klasse Object, da Ausdrücke Werte unterschiedlichen Typs zurückgeben können. Normalerweise sollte ein Ausdruck (expression) einen Wert zurückgeben, während eine Anweisung ((statement) nichts zurückgibt. Das ist der Unterschied zwischen ihnen. Im Falle einer Anweisung können wir null zurückgeben. Um jedoch eine NullPointerException zu vermeiden, geben wir anstelle von null ein Objekt vom Typ Object zurück, das global in der Klasse JimpleInterpreter definiert ist:
Die Klasse JimpleInterpreterVisitor erweitert die Klasse JimpleBaseVisitor und überschreibt nur die Methoden, an denen wir interessiert sind. Schauen wir uns die Implementierung des eingebauten println-Operators an, der in der Grammatik als println: ‚println‘ expression; beschrieben wird. Als erstes müssen wir den Ausdruck expression berechnen, dazu müssen wir die visit-Methode aufrufen und ihr das expression-Objekt aus dem aktuellen PrintlnContext übergeben. In der visitPrintln-Methode interessieren wir uns überhaupt nicht dafür, wie der Ausdruck ausgewertet wird, die entsprechende Methode ist für die Auswertung jeder Regel (Kontext) zuständig. Die Methode visitStringExpr.rpreter wird zum Beispiel verwendet, um ein String-Literal auszuwerten:
@Override
public Object visitPrintln(final JimpleParser.PrintlnContext ctx) {
final Object result = visit(ctx.expression());
System.out.println(result);
return null;
}
@Override
public Object visitStringExpr(final JimpleParser.StringExprContext ctx) {
// Gibt ein String-Literal zurück
return cleanStringLiteral(ctx.STRING_LITERAL().getText());
}
private String cleanStringLiteral(final String literal) {
// Anführungszeichen aus der Zeichenfolge entfernen
return literal.length() > 1 ? literal.substring(1, literal.length() – 1) : literal;
}
// Andere Methoden werden der Kürze halber weggelassen
}
Einzelheiten der Durchführung
Es ist nicht nötig, den gesamten Code der Interpreter-Implementierung wiederzugeben, der Link zu den Quellen befindet sich am Ende des Artikels. Ich möchte jedoch auf einige interessante Details eingehen.
Wie bereits erwähnt, basiert der Interpreter auf dem Visitor-Muster, welches die Knoten des AST-Baums besucht und die entsprechenden Anweisungen ausführt. Während der Codeausführung erscheinen neue Bezeichner (Variablen- und/oder Funktionsnamen) im aktuellen Kontext, die irgendwo gespeichert werden müssen. Zu diesem Zweck schreiben wir eine Klasse JimpleContext, die nicht nur diese Bezeichner, sondern auch den aktuellen Ausführungskontext von verschachtelten Codeblöcken und Funktionen speichert, da eine lokale Variable und/oder ein Funktionsparameter nach dem Verlassen ihres Geltungsbereichs gelöscht werden muss.
public Object handleFunc(FunctionSignature func, List<String> parameters, List<Object> arguments, FunctionDefinitionContext ctx) {
Map<String, Object> variables = new HashMap<>(parameters.size());
for (int i = 0; i < parameters.size(); i++) {
variables.put(parameters.get(i), arguments.get(i));
}
// Erstellen Sie einen neuen Funktionsparameterbereich und verschieben Sie ihn auf den Stapel
context.pushCallScope(variables);
// Ausführungsfunktionsausdrücke wurden der Kürze halber weggelassen
// Entfernen Sie den Umfang der Funktionsparameter vom Stapel
context.popCallScope();
return functionResult;
}
In unserer Sprache speichert eine Variable den Wert eines Typs, der zur Laufzeit definiert wird. In den folgenden Anweisungen kann dieser Typ dann geändert werden. Im Grunde genommen haben wir eine Sprache mit dynamischer Typisierung. Allerdings gibt es immer noch eine Typüberprüfung in Fällen, in denen es sinnlos ist, eine Operation auszuführen. Zum Beispiel kann eine Zahl nicht durch eine Zeichenkette dividiert werden.
Warum brauchen Sie zwei Durchgänge?
Die ursprüngliche Version des Interpreters sah vor, für jede Regel eine Methode zu implementieren. Findet beispielsweise die Methode zur Funktionsdeklaration eine Funktion mit diesem Namen (und der Anzahl der Parameter) im aktuellen Kontext, wird eine Ausnahme ausgelöst, andernfalls wird die Funktion dem aktuellen Kontext hinzugefügt. Die Methode des Funktionsaufrufs funktioniert auf die gleiche Weise. Wenn keine Funktion gefunden wird, wird eine Ausnahme ausgelöst, andernfalls wird die Funktion aufgerufen. Dieser Ansatz funktioniert, aber er erlaubt es nicht, eine Funktion aufzurufen, bevor sie definiert ist. Der folgende Code funktioniert zum Beispiel nicht:
println „Result is „ + add(result, 34)
fun add (a, b){
return a + b
}
In diesem Fall gibt es zwei Ansätze. Der erste besteht darin, dass eine Funktion vor ihrer Verwendung definiert werden muss (was für Sprachbenutzer nicht sehr praktisch ist). Die zweite besteht darin, zwei Durchgänge durchzuführen. Der erste Durchlauf wird benötigt, um alle Funktionen zu finden, die im Code definiert wurden. Der zweite Durchgang dient der direkten Ausführung des Codes. In meiner Implementierung habe ich den zweiten Ansatz gewählt. Man sollte die Implementierung der visitFunctionDefinition Methode in eine eigene Klasse verschieben, die die uns bereits bekannte generierte Klasse JimpleBaseVisitor<T> erweitert.
public class FunctionDefinitionVisitor extends JimpleBaseVisitor<Object> {
private final JimpleContext context;
private final FunctionCallHandler handler;
public FunctionDefinitionVisitor(final JimpleContext context, final FunctionCallHandler handler) {
this.context = context;
this.handler = handler;
}
@Override
public Object visitFunctionDefinition(final JimpleParser.FunctionDefinitionContext ctx) {
final String name = ctx.name.getText();
final List<String> parameters = ctx.IDENTIFIER().stream().skip(1).map(ParseTree::getText).toList();
final var funcSig = new FunctionSignature(name, parameters.size());
context.registerFunction(funcSig, (func, args) -> handler.handleFunc(func, parameters, args, ctx));
return VOID;
}
}
Jetzt haben wir eine Klasse, die wir verwenden können, bevor wir die Interpreterklasse direkt starten. Sie füllt unseren Kontext mit den Definitionen aller Funktionen, die wir in der Interpreterklasse aufrufen werden.
Wie sieht AST aus?
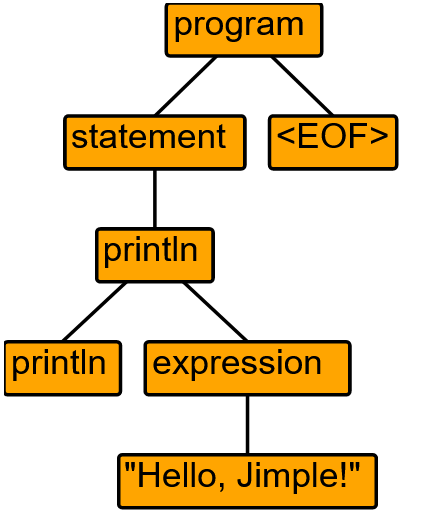
Um AST zu visualisieren, müssen wir das Dienstprogramm grun verwenden (siehe oben). Starten Sie dazu grun mit den Parametern Jimple program -gui (der erste Parameter ist der Name der Grammatik, der zweite Parameter ist der Name der Regel). Dadurch wird ein Fenster mit dem AST-Baum geöffnet. Bevor Sie dieses Dienstprogramm ausführen, müssen Sie den mit ANTLR erzeugten Code kompilieren.
antlr4.sh Jimple.g4
# Kompilieren Sie den generierten Code
javac –cp „.:/usr/lib/jvm/antlr-4.12.0-complete.jar„ Jimple*.java
# Führen Sie das grun aus
grun.sh Jimple program –gui
# Geben Sie den Code ein: „println „Hallo, Jimple!““.
# Drücken Sie Strg+D (Linux) oder Strg+Z (Windows)
Für den Jimple-Code println „Hello, Jimple!“ wird der folgende AST erzeugt:
Zusammenfassung
In diesem Artikel haben Sie sich mit Konzepten wie lexikalischen und syntaktischen Analysatoren vertraut gemacht. Sie haben das ANTLR-Tool verwendet, um solche Parser zu erzeugen. Sie haben gelernt, wie man eine ANTLR-Grammatik schreibt. Schließlich waren wir in der Lage, eine einfache Sprache zu erstellen, d. h. wir haben einen Interpreter für sie entwickelt. Als Bonus konnten wir die AST visualisieren.
Der gesamte Quellcode des Interpreters kann hier eingesehen werden.